Los sistemas basados en reglas son usados como una forma de almacenar y manipular el conocimiento e interpretarlo de una manera útil. También son usados en inteligencia artificial e investigación.
Un clásico ejemplo de sistemas basados en reglas son los sistemas expertos de un dominio en específico. Por ejemplo un sistema experto podrían ayudar a un doctor a escoger el diagnóstico correcto basado en un grupo de síntomas.
Definiciones de los Sistemas Expertos (SE)
Es un software que imita el comportamiento de un experto humano en la solución de un problema. Pueden almacenar conocimientos de expertos para un campo determinado y solucionar un problema mediante deducción lógica de conclusiones.
Son SE aquellos programas que se realizan haciendo explicito el conocimiento en ellos, que tienen información específica de un dominio concreto y que realizan una tarea relativa a este dominio.
Programas que manipulan conocimiento codificado para resolver problemas en un dominio especializado en un dominio que generalmente requiere de experiencia humana.
Programas que contienen tanto conocimiento declarativo (hechos a cerca de objetos, eventos y/o situaciones) como conocimiento de control (información acerca de los cursos de una acción), para emular el proceso de razonamiento de los expertos humanos en un dominio en particular y/o área de experiencia.
Software que incorpora conocimiento de experto sobre un dominio de aplicación dado, de manera que es capaz de resolver problemas de relativa dificultad y apoyar la toma de decisiones inteligentes en base a un proceso de razonamiento simbólico.
Aplicaciones
Sus principales aplicaciones se dan en las gestiones empresariales debido a que;
a) Casi todas las empresas disponen de un ordenador que realiza las funciones básicas de tratamiento de la información: contabilidad general, decisiones financieras, gestión de la tesorería, planificación, etc.
b) Este trabajo implica manejar grandes volúmenes de información y realizar operaciones numéricas para después tomar decisiones. Esto crea un terreno ideal para la implantación de los SE.
Además los SE también se aplican en la contabilidad en apartados como: Auditoria(es el campo en el que más aplicaciones de SE se está realizando) Fiscalidad, planificación, análisis financiero y la contabilidad financiera.
Áreas de Aplicación
Los SE se aplican a una gran diversidad de campos y/o áreas. A continuación se listan algunas de las principales:
Militar Informática Telecomunicaciones Química Derecho Aeronáutica Geología Arqueología Agricultura Electrónica Transporte Educación Medicina Industria Finanzas y Gestión
Ventajas
Estos programas proporcionan la capacidad de trabajar con grandes cantidades de información, que son uno de los grandes problemas que enfrenta el analista humano que puede afectar negativamente a la toma de decisiones pues el analista humano puede depurar datos que no considere relevantes, mientras un SE debido a su gran velocidad de proceso analiza toda la información incluyendo las no útiles para de esta manera aportar una decisión más sólida.
Limitaciones
Es evidente que para actualizar se necesita de reprogramación de estos (tal vez este sea una de sus limitaciones más acentuadas) otra de sus limitaciones puede ser el elevado costo en dinero y tiempo, además que estos programas son poco flexibles a cambios y de difícil acceso a información no estructurada.
Debido a la escasez de expertos humanos en determinadas áreas, los SE pueden almacenar su conocimiento para cuando sea necesario poder aplicarlo. Así mismo los SE pueden ser utilizados por personas no especializadas para resolver problemas. Además si una persona utiliza con frecuencia un SE aprenderá de él.
Por otra parte la inteligencia artificial no ha podido desarrollar sistemas que sean capaces de resolver problemas de manera general, de aplicar el sentido común para resolver situaciones complejas ni de controlar situaciones ambiguas.
El futuro de los SE da vueltas por la cabeza de cada persona, siempre que el campo elegido tenga la necesidad y/o presencia de un experto para la obtención de cualquier tipo de beneficio.
Arquitectura Básica de los Sistemas Expertos
Base de conocimientos. Es la parte del sistema experto que contiene el conocimiento sobre el dominio. Hay que obtener el conocimiento del experto y codificarlo en la base de conocimientos. Una forma clásica de representar el conocimiento en un sistema experto son lar reglas. Una regla es una estructura condicional que relaciona lógicamente la información contenida en la parte del antecedente con otra información contenida en la parte del consecuente.
Base de hechos (Memoria de trabajo). Contiene los hechos sobre un problema que se han descubierto durante una consulta. Durante una consulta con el sistema experto, el usuario introduce la información del problema actual en la base de hechos. El sistema empareja esta información con el conocimiento disponible en la base de conocimientos para deducir nuevos hechos.
Motor de inferencia. El sistema experto modela el proceso de razonamiento humano con un módulo conocido como el motor de inferencia. Dicho motor de inferencia trabaja con la información contenida en la base de conocimientos y la base de hechos para deducir nuevos hechos. Contrasta los hechos particulares de la base de hechos con el conocimiento contenido en la base de conocimientos para obtener conclusiones acerca del problema.
Subsistema de explicación. Una característica de los sistemas expertos es su habilidad para explicar su razonamiento. Usando el módulo del subsistema de explicación, un sistema experto puede proporcionar una explicación al usuario de por qué está haciendo una pregunta y cómo ha llegado a una conclusión. Este módulo proporciona beneficios tanto al diseñador del sistema como al usuario. El diseñador puede usarlo para detectar errores y el usuario se beneficia de la transparencia del sistema.
Interfaz de usuario. La interacción entre un sistema experto y un usuario se realiza en lenguaje natural. También es altamente interactiva y sigue el patrón de la conversación entre seres humanos. Para conducir este proceso de manera aceptable para el usuario es especialmente importante el diseño del interfaz de usuario. Un requerimiento básico del interfaz es la habilidad de hacer preguntas. Para obtener información fiable del usuario hay que poner especial cuidado en el diseño de las cuestiones. Esto puede requerir diseñar el interfaz usando menús o gráficos.
Ejemplo
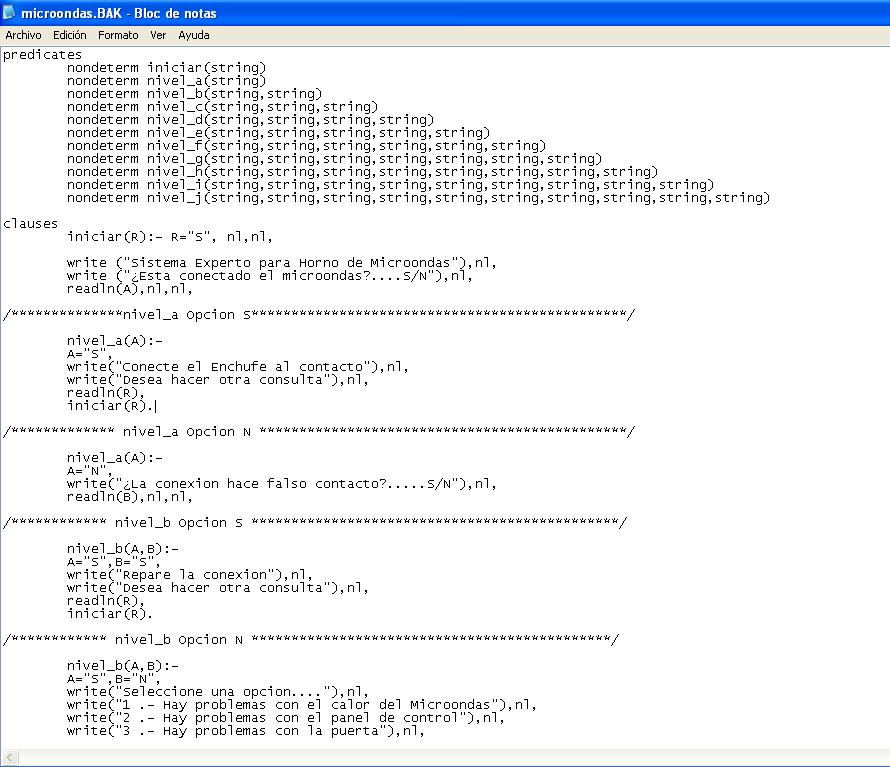
El ejemplo del que vamos a hablar es de un sistema experto para reparar un microondas, este sistema experto fue desarrollado en prolog y básicamente tiene como objetivo el proporcionar una guía para la solución de los problemas o fallas más comunes que puede presentar el horno de microondas.
Las preposiciones simples que se utilizaron son:
A1 – Está conectado el microondas.
B1 – La conexión hace falso contacto.
C1 – Hay problemas con el calor del microondas.
C2 – Hay problemas con el panel de control.
C3 – Hay problemas con la puerta.
C4 – Hay otros problemas.
D1 – Hay calor débil.
D2 – Existe calor intermitente.
D3 – Existe calor.
D4 – La pantalla muestra código anormal.
D5 – La puerta se cierra de golpe para que funcione.
D6 – Algo estalló durante el tiempo de cocción.
E1 – El sonido del tarareo esta bajo.
E2 – Las conexiones de la terminal están en buenas condiciones.
E3 – Todo funciona correctamente.
E4 – Observa el código F1, F2, F3, F4 o F6.
E5 – Observa el código F5.
E6 – Observa el código S1.
E7 – Observa el código CS.
E8 – Observa el código PPPP.
E9 – Los botones funcionan correctamente.
E10 – La conexión del interruptor trabaja.
E11 – El microondas trabaja cuando se cierra la puerta.
E12 – Se encuentra chispeado fuera de la parte posterior del microondas.
E13 – Se apaga el microondas en el tiempo de cocinado.
F1 – El tubo del magnetrón funciona.
F2 – Expide un olor ardiente.
F3 – Los conectores del filamento del magnetrón están flojos.
F4 – Expide algún olor.
F5 – El botón Stara funciona correctamente.
F6 – Aparece “F12” en la pantalla.
F7 – La puerta del microondas esta quebrada.
F8 – Despidió olor a quemado.
F9 – Se apagó el microondas por problemas de energía.
G1 – El triac esta funcionando.
G2 – Aparece el código “F11”.
G4 – El cierre de la puerta funciona.
G5 – Las conexiones funcionan adecuadamente.
H1 – Trabajan las luces y el ventilador.
H2 – Funciona el módulo de control de calor.
H3 – El contador de tiempo del tablero funciona bien.
H4 – El contacto del fusible funciona bien.
H5 – Se escuchó un ruido en el microondas.
I1 – El triac funciona.
I2 – El tiempo transcurrido de cocción cambia por si solo.
I3 – Recibe energía.
I4 – El ventilador funciona.
I5 – Se forman arcos en el fondo del microondas.
J1 – El regulador auxiliar proporciona voltaje al transformador.
J2 – Funciona el tablero de memoria extendido.
J3 – Hay restos de alimento en el microondas.
J4 – Está girando la placa giratoria.
Árbol de Decisión
Camino Solución
1) ¬A1 èS1
2) A1 Λ B1 èS2
3) A1 Λ ¬B1 Λ C1 Λ D1 Λ E1 Λ F1 èS3
4) A1 Λ ¬B1 Λ C1 Λ D1 Λ E1 Λ ¬F1 èS4
5) A1 Λ ¬B1 Λ C1 Λ D1 Λ ¬E1 Λ F2 èS5
6) A1 Λ ¬B1 Λ C1 Λ D1 Λ ¬E1 Λ ¬F2 èS6
7) A1 Λ ¬B1 Λ C1 Λ D2 Λ ¬E2 èS7
8) A1 Λ ¬B1 Λ C1 Λ D2 Λ ¬E2 Λ F3èS8
9) A1 Λ ¬B1 Λ C1 Λ D2 Λ ¬E2 Λ ¬F3èS9
10) A1 Λ ¬B1 Λ C1 Λ ¬D3 Λ E3 èS10
11) A1 Λ ¬B1 Λ C1 Λ ¬D3 Λ ¬E3 Λ F4 Λ G1 èS11
12) A1 Λ ¬B1 Λ C1 Λ ¬D3 Λ ¬E3 Λ F4 Λ ¬G1 Λ H1 èS12
13) A1 Λ ¬B1 Λ C1 Λ ¬D3 Λ ¬E3 Λ F4 Λ ¬G1 Λ ¬H1 èS13
14) A1 Λ ¬B1 Λ C1 Λ ¬D3 Λ ¬E3 Λ ¬F4 Λ G2 èS14
15) A1 Λ ¬B1 Λ C1 Λ ¬D3 Λ ¬E3 Λ ¬F4 Λ ¬G2 Λ ¬H2 èS15
16) A1 Λ ¬B1 Λ C1 Λ ¬D3 Λ ¬E3 Λ ¬F4 Λ ¬G2 Λ H2 Λ ¬I1 èS16
17) A1 Λ ¬B1 Λ C1 Λ ¬D3 Λ ¬E3 Λ ¬F4 Λ ¬G2 Λ H2 Λ I1 Λ ¬J2 èS17
18) A1 Λ ¬B1 Λ C1 Λ ¬D3 Λ ¬E3 Λ ¬F4 Λ ¬G2 Λ H2 Λ I1 Λ J2 èS18
19) A1 Λ ¬B1 Λ C2 Λ D4 Λ E4 èS19
20) A1 Λ ¬B1 Λ C2 Λ D4 Λ E5 èS20
21) A1 Λ ¬B1 Λ C2 Λ D4 Λ E6 èS21
22) A1 Λ ¬B1 Λ C2 Λ D4 Λ E7 èS22
23) A1 Λ ¬B1 Λ C2 Λ D4 Λ E8 èS23
24) A1 Λ ¬B1 Λ C2 Λ ¬D4 Λ ¬E9 Λ F5 èS24
25) A1 Λ ¬B1 Λ C2 Λ ¬D4 Λ ¬E9 Λ ¬F5 èS25
26) A1 Λ ¬B1 Λ C2 Λ ¬D4 Λ E9 Λ F6 èS26
27) A1 Λ ¬B1 Λ C2 Λ ¬D4 Λ E9 Λ ¬F6 Λ G3 èS27
28) A1 Λ ¬B1 Λ C2 Λ ¬D4 Λ E9 Λ ¬F6 Λ ¬G3 Λ ¬H3 Λ I2 èS28
29) A1 Λ ¬B1 Λ C2 Λ ¬D4 Λ E9 Λ ¬F6 Λ ¬G3 Λ ¬H3 Λ I2 Λ ¬J2 èS29
30) A1 Λ ¬B1 Λ C2 Λ ¬D4 Λ E9 Λ ¬F6 Λ ¬G3 Λ ¬H3 Λ I2 Λ J2 èS30
31) A1 Λ ¬B1 Λ C2 Λ ¬D4 Λ E9 Λ ¬F6 Λ ¬G3 Λ H3 Λ I3 èS31
32) A1 Λ ¬B1 Λ C2 Λ ¬D4 Λ E9 Λ ¬F6 Λ ¬G3 Λ H3 Λ ¬I3 èS32
33) A1 Λ ¬B1 Λ C3 Λ D5 Λ E10 èS33
34) A1 Λ ¬B1 Λ C3 Λ D5 Λ ¬E10 èS34
35) A1 Λ ¬B1 Λ C3 Λ ¬D5 Λ ¬E11 èS35
36) A1 Λ ¬B1 Λ C3 Λ ¬D5 Λ E11 Λ ¬F7 è S36
37) A1 Λ ¬B1 Λ C3 Λ ¬D5 Λ E11 Λ F7 Λ G4 èS37
38) A1 Λ ¬B1 Λ C3 Λ ¬D5 Λ E11 Λ F7 Λ ¬G4 è S38
39) A1 Λ ¬B1 Λ C4 Λ D6 Λ E12 èS39
40) A1 Λ ¬B1 Λ C4 Λ D6 Λ ¬E12 Λ F8 èS40
41) A1 Λ ¬B1 Λ C4 Λ D6 Λ ¬E12 Λ ¬F8 èS41
42) A1 Λ ¬B1 Λ C4 Λ ¬D6 Λ ¬E13 èS42
43) A1 Λ ¬B1 Λ C4 Λ ¬D6 Λ E13 Λ F9 èS43
44) A1 Λ ¬B1 Λ C4 Λ ¬D6 Λ E13 Λ ¬F9 Λ G5 Λ H4 èS44
45) A1 Λ ¬B1 Λ C4 Λ ¬D6 Λ E13 Λ ¬F9 Λ G5 Λ ¬H4 èS45
46) A1 Λ ¬B1 Λ C4 Λ ¬D6 Λ E13 Λ ¬F9 Λ ¬G5 Λ H5 Λ I4 èS46
47) A1 Λ ¬B1 Λ C4 Λ ¬D6 Λ E13 Λ ¬F9 Λ ¬G5 Λ H5 Λ ¬I4 èS47
48) A1 Λ ¬B1 Λ C4 Λ ¬D6 Λ E13 Λ ¬F9 Λ ¬G5 Λ ¬H5 Λ I5 Λ J3 èS48
49) A1 Λ ¬B1 Λ C4 Λ ¬D6 Λ E13 Λ ¬F9 Λ ¬G5 Λ ¬H5 Λ I5 Λ ¬J3 èS49
50) A1 Λ ¬B1 Λ C4 Λ ¬D6 Λ E13 Λ ¬F9 Λ ¬G5 Λ ¬H5 Λ ¬I5 Λ J4 èS50
51) A1 Λ ¬B1 Λ C4 Λ ¬D6 Λ E13 Λ ¬F9 Λ ¬G5 Λ ¬H5 Λ ¬I5 Λ ¬J4 èS51
Por ultimo les dejo unas imágenes del código y del sistema experto ya funcionando.